Today I was mob programming with Square's Mobile & Performance Reliability team and we toyed with an interesting idea.
Our codebase has classes that represent screens a user can navigate to. These classes are defined in modules, and these modules have an owner team defined.
When navigating to a screen, we wanted to have the owner team information available, at runtime. We created a build tool that looks at about 1000 Screen classes, determines the owner team, and generates a class to do the lookup at runtime.
The generated code looked like this:
object ScreenOwnership {
private val classNameToOwner = mapOf(
"com.example.feature1.Screen1" to "Team A",
"com.example.feature2.Screen2" to "Team A",
"com.example.feature3.Screen3" to "Team B",
)
fun ownerOf(screenClass: KClass<Screen>): String {
return classNameToOwner.getValue(screenClass.java.name)
}
}
This works, but it feels a bit wasteful. Let's explore why.
Yes, I'm aware, "Premature optimization is the root of all evil". Our goal here was to think through the impact of this implementation and come up with an alternative implementation, for fun. Don't be a killjoy.
mapOf and pairs
mapOf(vararg pairs: Pair<K, V>) is a nice utility to create a map (more specifically, a LinkedHashMap) but using that syntax leads to the creation of a temporary vararg array of size 1000, as well as 1000 temporary Pair instances.
Memory hoarding
Let's look at the retained size of the map we just created:
~30 characters per class name * 2 bytes per character = 60 bytes per entry
Each entry is stored as a LinkedHashMapEntry which adds 2 references to HashMap.Node which itself holds 3 references and 1 int. On a 64bit
VM that's 5 references * 8 bytes, plus 4 bytes for the int: 44 bytes per entry.
So for the entries alone we're at (60 + 44) * 1000 = 104 KB.
The default load factor is 75%, which means the size of the array backing the hashmap must always be at least 25% greater than the number of entries. And the array size has to be a factor of 2. So, for 1000 entries, that's an object array of size 2048: 2048 * 8 = 16,314 bytes.
The total retained size of the map is ~120 KB. Can we do better?
Could we make it... 0?
100% code-based map
What if we generate code that returns the right team for a given screen, instead of creating a map?
object ScreenOwnership {
fun ownerOf(screenClass: KClass<Screen>): String {
return when(screenClass.java.name) {
"com.example.feature1.Screen1" -> "Team A"
"com.example.feature2.Screen2" -> "Team B"
"com.example.feature2.Screen3" -> "Team C"
else -> error("Unknown screen class ${screenClass.java.name}")
}
}
}
The Kotlin compiler is smart and actually generates code that checks the string against its hashcode first, which looks like this:
object ScreenOwnership {
fun ownerOf(screenClass: KClass<Screen>): String {
val screenClassName = screenClass.java.name
return when (screenClassName.hashCode()) {
1179818499 -> if (screenClassName == "com.example.feature1.Screen1")
"Team A"
else
null
-627635963 -> if (screenClassName == "com.example.feature2.Screen2")
"Team B"
else
null
-627635962 -> if (screenClassName == "com.example.feature3.Screen3")
"Team C"
else
null
else -> null
} ?: error("Unknown screen class $screenClassName")
}
}
Since we know the full list of screen classes, we can check ahead of time whether there's any hashcode conflict, and if not, we can generate code that directly associates the hashcode of the screen class name to the corresponding team:
object ScreenOwnership {
fun ownerOf(screenClass: KClass<Screen>): String {
val screenClassName = screenClass.java.name
return when (screenClassName.hashCode()) {
1179818499 -> "Team A"
-627635963 -> "Team B"
-627635962 -> "Team C"
else -> error("Unknown screen class $screenClass")
}
}
}
Linear scan?
HashMap.get(key) calls key.hashCode() , wrangles that hashcode modulo the size of the backing array, which gives it an index to look up a linked list of entries in the backing array. The higher the load factor, the more hash collisions and the larger the linked lists. In other words, assuming a reasonable load factor, HashMap.get(key) has constant time performance - O(1) time complexity - to locate the entry, however it does need to follow references which might require loading a different page of memory.
Contrast this with our when based implementation:
when (screenClassName.hashCode()) {
1179818499 -> "Team A"
-627635963 -> "Team B"
-627635962 -> "Team C"
}
This code seems to imply that we need to check the hashcode against every single value. That's a linear scan, O(n) time complexity. Oh no!
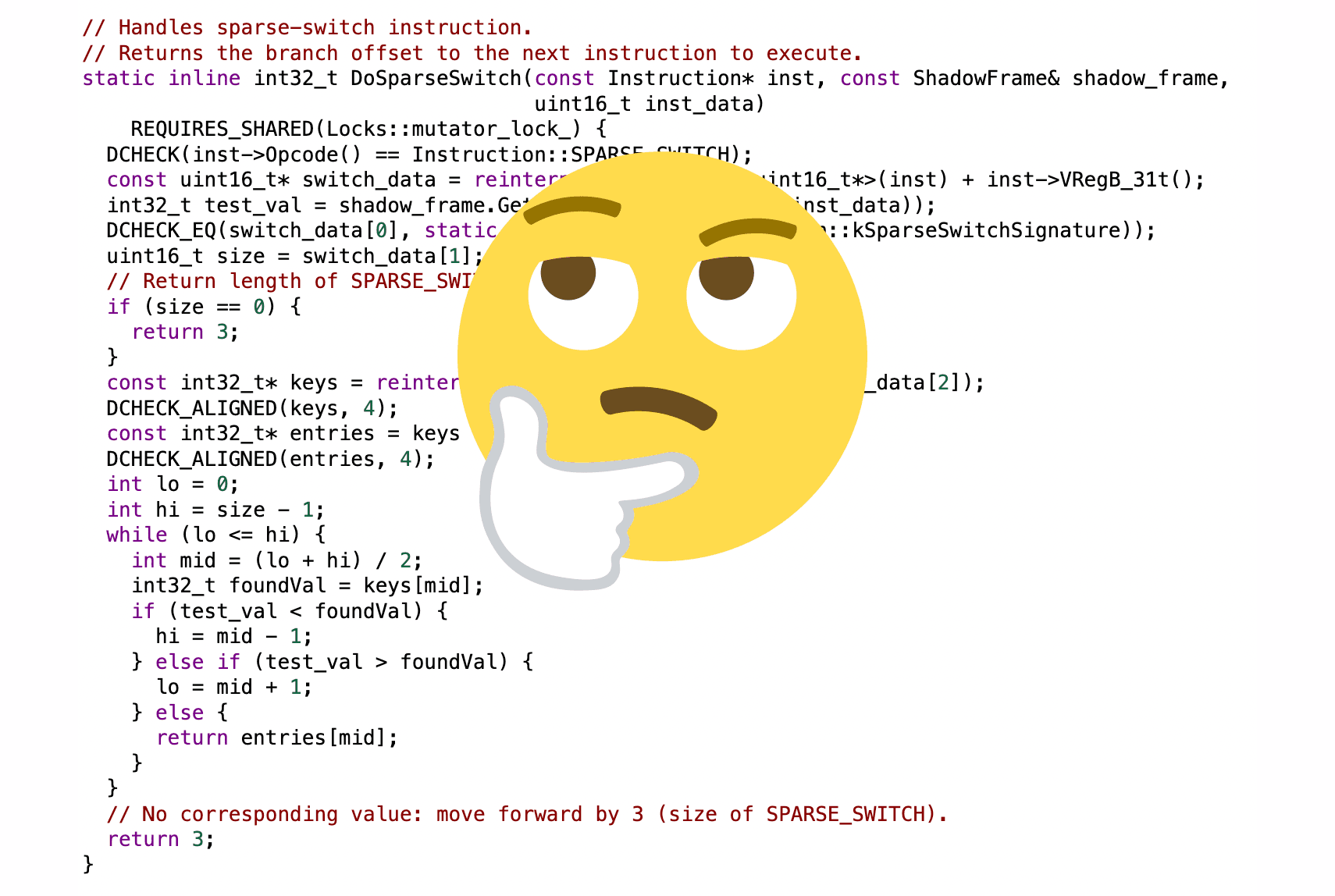
Fortunately for us, the Android ART runtime will transform a switch on Integers and sort the branches so that it can then perform a binary search at runtime (source) to jump to the correct instruction:
static inline int32_t DoSparseSwitch(const Instruction* inst, const ShadowFrame& shadow_frame,
uint16_t inst_data)
{
const uint16_t* switch_data = reinterpret_cast<const uint16_t*>(inst) + inst->VRegB_31t();
int32_t test_val = shadow_frame.GetVReg(inst->VRegA_31t(inst_data));
uint16_t size = switch_data[1];
if (size == 0) {
return 3;
}
const int32_t* keys = reinterpret_cast<const int32_t*>(&switch_data[2]);
const int32_t* entries = keys + size;
int lo = 0;
int hi = size - 1;
while (lo <= hi) {
int mid = (lo + hi) / 2;
int32_t foundVal = keys[mid];
if (test_val < foundVal) {
hi = mid - 1;
} else if (test_val > foundVal) {
lo = mid + 1;
} else {
return entries[mid];
}
}
return 3;
}
With a binary search, we're looking at O(log n) time complexity. Not bad!
Scatter Map
I would be remiss if I did not mention Romain Guy's recent article, A Better Hash Map, which inspired this article. ScatterMap significantly improves the memory footprint & memory cache behavior over HashMap. It's very cool! Not as cool as generating a code-based map though 😜.